Prosessien läpivalaisu on avain faktapohjaisiin päätöksiin
Artikkeli on julkaistu Helsingin Sanomien Teknologia-liitteessä 19.10.2022. Prosessilouhinnan avulla yritys voi paikantaa tehottomia toimintojaan sekä...


Finnish public service organizations face a growing need to describe their information architecture and information portfolio. Its main drivers are EU’s General Data Protection Regulation (GDPR) and the new Information Management Act in Finland (entering into force 1.1.2020). Just as organizations need to describe and maintain their service and application portfolio, they need to understand and describe their information portfolio, i.e. information capital.
The information architecture of projects or business services is usually described in the form of domain concepts (conceptual data entities) and logical data entities, but on organizational level this would result in a model being too fine-grained, including too many entities, beyond understandable. In order to describe the organization’s information architecture, we need a more abstract, higher level concept.
JHS 179 recommendation (regarding enterprise architecture planning and development, created for Finnish public sector organizations in Finnish language) introduces data groups and main data groups, suitable for this purpose. As defined in JHS179, data group is “a high-level collection of data, derived from process and information needs”. Using them enables the organization to understand its information portfolio on a suitable abstraction level. This blog explains how to explore data groups according to JHS179 recommendation using QPR EnterpriseArchitect tool.
The collection of data groups can be visualized using data group diagram, where data groups form a hierarchy. The examples in this article are from a Finnish city’s education and daycare services organization’s data group diagram.
Main data groups are organized into data domains (groups), according to service area (inside the organization).
Example: Daycare and pre-school data
/Blogi%20(FI)/Tietoryhmien%20laaja%20kuvaus%201/Blogi%20-%20Main%20Data%20Group%20-%20Image.png?width=913&name=Blogi%20-%20Main%20Data%20Group%20-%20Image.png)
”Main data group is a high-level collection of data, derived from process and information needs (JHS179)”. In practice, it is a collection of data groups.
Example: Daycare information
/Blogi%20(FI)/Tietoryhmien%20laaja%20kuvaus%201/Blogi%20-%20Main%20Data%20Group%202%20-%20Image.png?width=783&name=Blogi%20-%20Main%20Data%20Group%202%20-%20Image.png)
”Data group is a low-level collection of data, derived from process and information needs (JHS179)”.
Example: Daycare children
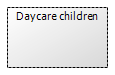
The next step is to consider mapping data groups to the information elements described in projects and services (i.e. to domain concepts and logical data elements mentioned in the beginning). A data group, as the name implies, is a set of interrelated data. The example above (Daycare children) includes children's personal information, address(es) and health information. The content of a data group can be described as a set of domain concepts (conceptual data entities) and their relationships, i.e. in the form of a domain model. The contents of a data group can also be described on a logical level, that is, by means of logical data entities and their relationships, i.e. in a logical data model.
The metamodel below forms a coherent hierarchical chain (from top to bottom).
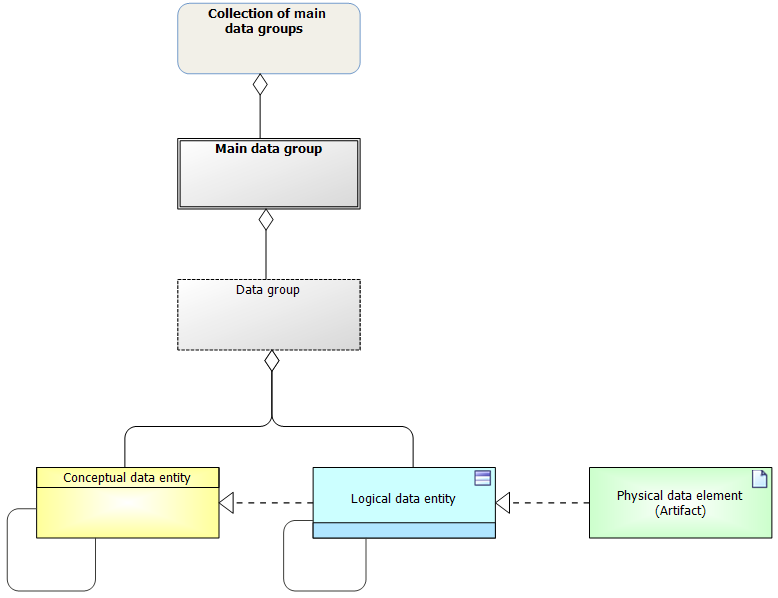
Although information modeling is a nice task 😊, one must benefit from it as well. Next, let us see how to discover and use data groups, through a practical example.
Data groups can be derived in two ways: bottom-up or top-down. Top-down approach starts from the collection of the organization’s all information, which is broken down to smaller sets, according to a previously agreed criteria, e.g. the organization’s main business lines, service areas or top-level product groups. Breaking down continues to the next levels, until you get reasonable sized information units: data groups.
This blog focuses on the bottom-up approach, which has been used in the previously mentioned city. Its process and application architecture has been already described at some level, providing lots of input for discovering data groups.
In the previously mentioned city, data groups are being utilized in information management, since data groups form the organization-wide information map.
While planning a new service, its related data groups are refined into a domain model. Data groups are also utilized in sketching information flows on high-level. In the early phase of planning the service and its supporting application(s), data groups can be used to describe what information is handed over to another authority or company, and what information the future application is supposed to provide or receive from other applications.
Data groups can be used as well to describe the organization’s registers, data pools and data stores.
Data groups are also useful for finding new analysis and reporting possibilities, for example in predicting future service needs.
In another case, at Traficom (Finnish Transport and Communications Agency), data groups are described on enterprise level, explored using top-down approach. They are linked to projects by instantiating the relevant enterprise-level data groups on the project-level diagrams; i.e. data groups which will be changed or used in the new application/functionality developed by the project in question. In addition, the project-specific domain concepts and logical data entities are linked to the above data groups, refining the data group firstly on conceptual, then on logical level as described in the metamodel. Thus, the project (and its planned outcome) is connected to the enterprise architecture also from the viewpoint of information architecture.
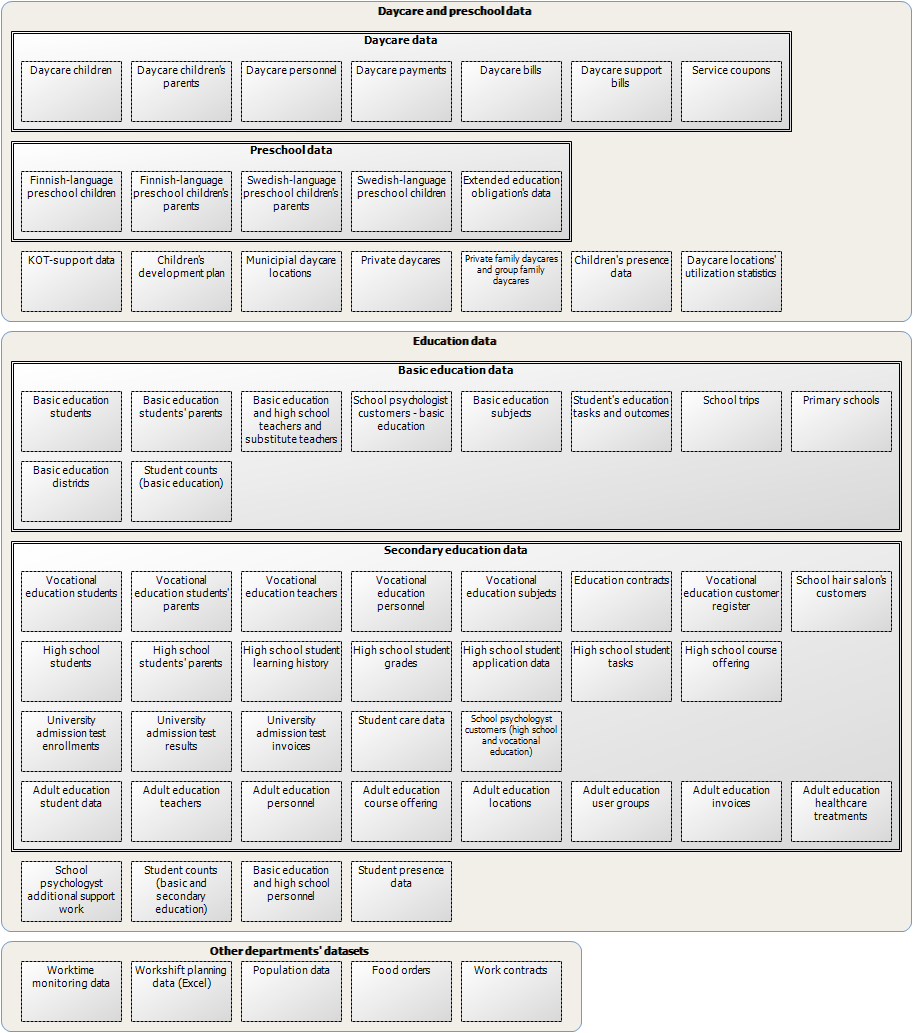
The data group diagram below includes all data groups of the above-mentioned Finnish city’s daycare and education services organization. These data groups are discovered using the previously described bottom-up approach, and utilized now in information management as well as in services development.

Jaa

Artikkeli on julkaistu Helsingin Sanomien Teknologia-liitteessä 19.10.2022. Prosessilouhinnan avulla yritys voi paikantaa tehottomia toimintojaan sekä...

Information architecture (IA) is all about organizing, structuring, and labeling content in an effective and sustainable way. The idea is to help users find...

Olen viime vuosina saanut läheltä seurata muutamia dokumenttien- ja sisällönhallinnan tietojärjestelmähankkeita. Digitalisaation myötä myös strukturoimaton...

Keväällä 2020 aloitimme yhdessä Sitran kanssa uraauurtavan projektin, jossa läpivalaisimme ja analysoimme datan avulla Suomen lainsäädännön prosessit vuosilta...
Blogi
Digitalisaation myötä myös strukturoimaton tieto erilaisten esitettävien sisältöjen ja dokumenttien muodossa lisääntyy valtavaa vauhtia.
QPR:n uraauurtava konsultti Jaakko Riihinen pohtii blogissaan, miten dokumentinhallinta kannattaisi järjestää.