Prosessien läpivalaisu on avain faktapohjaisiin päätöksiin
Artikkeli on julkaistu Helsingin Sanomien Teknologia-liitteessä 19.10.2022. Prosessilouhinnan avulla yritys voi paikantaa tehottomia toimintojaan sekä...


Instead of focusing solely on master data and its management, companies should really be putting their efforts into data reusability and data quality if they want to become masters of the information they create and gather instead of slaves to it.
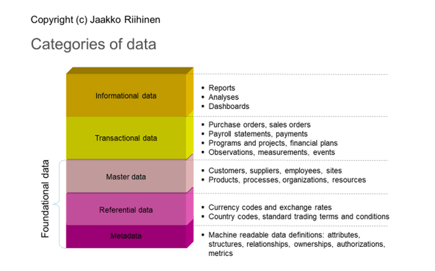
Master data is just one layer in data categorisation and is no more or less important than the other layers –i.e. metadata, reference data, and transactional and informational data (see the illustration above). If we think of these layers as a house, metadata and reference and master data are the foundations on top of which we add transactional data and then analyse it, while master data is the cornerstone. So, when the foundations are weak, instead of big data we get a data swamp – a confusing mass of data that no one knows how to use.
A growing demand for data analysts is usually a good indication that a company is at the very least becoming edgy about its data, and probably trying to cover up issues with low-quality data. Typically, a data analyst spends 80 % of their time fixing data and only 20 % for actually performing analysis. This is an unsustainable and costly way to work. In addition, many organizations believe that simply introducing a new system will solve all their problems with data quality and reusability, and that they won’t then need to make changes to their data foundations. The end result is that fragmented data volume grows across organisation enormously.
Master data management (MDM) has hogged the spotlight as a method to improve data quality in organisations, and the many MDM-related articles, books, and presentations out there have a great deal of useful information on how to approach MDM and what can and does go wrong. However, putting all your eggs in one basket is never a good idea – MDM is too narrow a scope when it comes to ensuring data quality; instead, data reusability should be the focus. Data reusability challenges organisations to focus also on data sources, structure, usage and its lifecycle. With reusability as the focus the data entered into a system becomes information, knowledge and wisdom. We want the data quality to be as good as it can be from the point it is created right through its useful lifecycle. One example of a good data quality is that data collected by one system can be reused as it is across different systems. More specifically, according to ISO 8000 data quality can be defined and measured according to its syntactic, semantic and pragmatic quality. We want the flexibility that reusable data can provide to organisations.
In the modern digital era we need data that we can work with today and tomorrow. Data needs to be ready for AI (artificial intelligence) use. Good-quality data that is reusable is a powerful tool to enable flexibility and success, helping organisations move forward with confidence, instead of holding them back.


Jaa

Artikkeli on julkaistu Helsingin Sanomien Teknologia-liitteessä 19.10.2022. Prosessilouhinnan avulla yritys voi paikantaa tehottomia toimintojaan sekä...

Information architecture (IA) is all about organizing, structuring, and labeling content in an effective and sustainable way. The idea is to help users find...

Olen viime vuosina saanut läheltä seurata muutamia dokumenttien- ja sisällönhallinnan tietojärjestelmähankkeita. Digitalisaation myötä myös strukturoimaton...

Keväällä 2020 aloitimme yhdessä Sitran kanssa uraauurtavan projektin, jossa läpivalaisimme ja analysoimme datan avulla Suomen lainsäädännön prosessit vuosilta...
Blogi
Digitalisaation myötä myös strukturoimaton tieto erilaisten esitettävien sisältöjen ja dokumenttien muodossa lisääntyy valtavaa vauhtia.
QPR:n uraauurtava konsultti Jaakko Riihinen pohtii blogissaan, miten dokumentinhallinta kannattaisi järjestää.